JVM 内存结构、垃圾回收机制与参数调优 数据处理与存储服务的核心支持
在现代企业级应用中,数据处理和存储服务通常面临着高并发、大数据量和低延迟的严苛要求。Java虚拟机(JVM)作为这些服务的主流运行环境,其内部的内存管理机制、垃圾回收(GC)策略以及参数调优能力,直接决定了服务的性能、稳定性和可扩展性。深入理解JVM的内存结构与GC原理,并进行有效的参数调优,是构建高效、可靠数据处理与存储支持服务的技术基石。
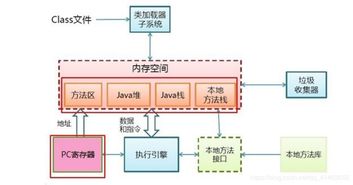
一、JVM内存结构:数据处理的运行时舞台
JVM内存区域主要划分为线程共享区和线程私有区,共同构成了应用程序数据处理的运行时舞台。
- 线程共享区(所有线程共享)
- 堆(Heap):这是JVM管理的最大一块内存区域,也是垃圾回收器工作的主要场所。几乎所有的对象实例和数组都在这里分配内存。堆是数据处理服务的核心区域,存放着业务数据对象、缓存对象等。为了优化GC性能,堆内部分为新生代(Young Generation)和老年代(Old Generation)。新生代又细分为Eden区和两个Survivor区(S0, S1)。
- 方法区(Method Area):用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。在JDK 8及之后,永久代(PermGen)被元空间(Metaspace)取代,元空间使用本地内存,减少了OutOfMemoryError的风险。
- 线程私有区(每个线程独有)
- 程序计数器(Program Counter Register):指向当前线程正在执行的字节码指令地址。
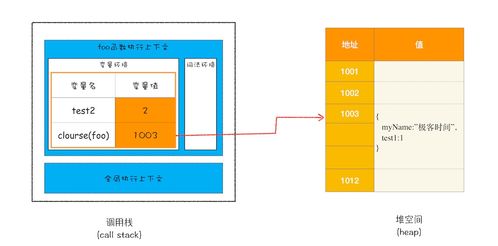
- Java虚拟机栈(Java Virtual Machine Stacks):每个方法执行时会创建一个栈帧,用于存储局部变量表、操作数栈、动态链接、方法出口等信息。局部变量表存放了基本数据类型和对象引用。
- 本地方法栈(Native Method Stack):为JVM使用到的本地(Native)方法服务。
对于数据处理服务,堆内存的规模和结构是性能的关键。过小的堆容易引发频繁的GC甚至内存溢出;过大的堆则可能导致单次GC停顿时间过长。合理划分新生代与老年代的比例,能有效管理不同生命周期对象,提升GC效率。
二、垃圾回收(GC)机制:自动内存管理引擎
GC负责自动回收堆中不再使用的对象,释放内存。其核心是“分代收集”理论,针对不同区域采用不同的算法。
- 新生代GC(Minor GC):对象优先在Eden区分配。当Eden区满时,触发Minor GC。存活的对象会被移动到其中一个Survivor区,年龄加1。随后Eden区和正在使用的Survivor区被清空。对象在Survivor区之间来回拷贝,直到年龄达到阈值(默认15),则晋升到老年代。新生代GC通常使用复制算法,速度快,但会浪费一部分内存(Survivor区)。
- 老年代GC(Major GC / Full GC):当老年代空间不足、方法区空间不足或调用
System.gc()时,可能触发Full GC,这会同时清理新生代、老年代和方法区。Full GC速度慢,停顿时间长,对服务影响巨大,应尽量避免。老年代GC通常使用标记-清除或标记-整理算法。
- 主流垃圾收集器:
- Serial / Serial Old:单线程收集器,简单高效,适用于客户端或小内存应用。
- Parallel Scavenge / Parallel Old:JDK 8默认组合,多线程并行收集,追求高吞吐量。适合后台计算、批处理任务。
- CMS(Concurrent Mark Sweep):以获取最短回收停顿时间为目标,大部分工作可与用户线程并发执行。适合对延迟敏感的服务,但会产生内存碎片。
- G1(Garbage-First):JDK 9及之后的默认收集器。它将堆划分为多个大小相等的独立区域(Region),能预测停顿时间,并优先回收垃圾最多的区域。兼顾吞吐量和低延迟,是大内存、多核处理器的首选,非常适合大规模数据处理服务。
- ZGC / Shenandoah:新一代超低延迟收集器,停顿时间可控制在10毫秒以内,适用于对延迟有极端要求的场景。
三、JVM参数调优:为数据处理服务定制运行时
调优的目标是在给定的硬件资源下,平衡吞吐量、延迟和内存占用。以下是针对数据处理与存储服务的关键调优思路和参数示例。
- 堆内存设置:这是最基础的调优。
-Xms和-Xmx:设置堆的初始大小和最大大小。通常将它们设为相同值,以避免堆在运行时动态调整带来的性能波动。例如:-Xms4g -Xmx4g。大小需根据系统总内存和数据量设定,建议不超过物理内存的50%-70%。
-Xmn:设置新生代大小。增大新生代可以减少对象过早进入老年代,但会减小老年代,可能增加Full GC频率。通常为整个堆的1/3到1/4。也可用-XX:NewRatio设置新生代与老年代的比例。
- 选择合适的垃圾收集器:
- 对于高吞吐量的批处理任务:可使用默认的Parallel Scavenge/Old,或显式指定
-XX:+UseParallelGC。
- 对于在线查询、实时数据处理等对延迟敏感的服务:强烈推荐使用G1收集器。参数:
-XX:+UseG1GC。可以进一步设置预期最大停顿时间:-XX:MaxGCPauseMillis=200(目标200毫秒)。
- 对于内存非常大(如数百GB)且要求极低延迟的场景:可考虑ZGC (
-XX:+UseZGC) 或 Shenandoah (-XX:+UseShenandoahGC)。
- GC日志与分析:开启GC日志是调优的第一步。
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/path/to/gc.log
- 使用工具(如GCViewer, GCEasy)分析日志,关注:Full GC频率、单次GC停顿时间、吞吐量(应用运行时间/总时间)。
- 针对数据处理服务的特殊优化:
- 大对象处理:频繁创建大对象(如大数组)会直接进入老年代,容易引发Full GC。可考虑调整阈值
-XX:PretenureSizeThreshold,或优化代码使用对象池。
- 元空间(Metaspace):数据处理框架(如Spark、Flink)和依赖众多,可能加载大量类。需监控并适当限制元空间:
-XX:MaxMetaspaceSize=256m,防止无限制膨胀。
- 直接内存:NIO、Netty等网络通信或缓存组件会使用直接内存(堆外内存)。其大小受
-XX:MaxDirectMemorySize限制,不足也会引发Full GC。
- 避免显式System.gc():可通过
-XX:+DisableExplicitGC禁用,但需确保使用的第三方库(如NIO)不会因此出现问题。
四、实践:构建稳定的数据处理支持服务
- 监控先行:在生产环境中部署APM工具(如Prometheus + Grafana, SkyWalking)或JMX,实时监控堆内存使用率、GC频率与耗时、线程状态等关键指标。
- 压力测试:在上线前,使用模拟真实数据量和访问模式的压力测试,观察JVM表现,并根据GC日志调整参数。
- 循序渐进:调优是一个迭代过程。每次只调整1-2个参数,观察效果,再决定下一步。没有一套放之四海而皆准的参数。
- 结合应用特点:不同的数据处理框架(如Spark内存计算、Elasticsearch索引存储、Kafka消息队列)对内存和GC有不同偏好,需参考其官方最佳实践进行配置。
****:JVM的内存结构为数据处理服务提供了灵活而强大的运行时容器,垃圾回收机制是其高效运转的自动清洁工。通过深入的原理理解和精细的JVM参数调优,我们可以最大限度地发挥硬件潜力,确保数据处理与存储支持服务在高负载下依然保持高性能、低延迟和高可靠性,从而为上层业务提供坚实的技术支撑。
如若转载,请注明出处:http://www.qjxmcdh.com/product/9.html
更新时间:2026-06-18 02:05:02