HBase数据存储格式、数据处理与存储支持服务详解
HBase作为Apache Hadoop生态系统中的一个关键组件,是一个高可靠性、高性能、面向列、可伸缩的分布式NoSQL数据库。它构建在HDFS之上,为海量数据的存储和实时读写访问提供了强大的支持。理解其核心的数据存储格式、数据处理机制以及它如何提供数据存储支持服务,对于有效利用HBase至关重要。
一、HBase数据存储格式
HBase的数据模型虽然从概念上可以理解为一张稀疏的多维映射表,但其物理存储格式经过高度优化,以实现高效的读写和扫描操作。
- 逻辑视图:表、行、列族、列限定符与时间戳
- 表(Table):数据的逻辑集合。
- 行(Row):数据存储的基本单位,由一个唯一的行键(RowKey)标识。所有行键按字典顺序排序,这是HBase实现快速范围查询的基础。
- 列族(Column Family):一组相关列的集合。必须在创建表时预先定义。物理存储上,同一列族下的所有数据会存储在同一个存储文件(HFile)中,因此将访问模式相似的列放在同一个列族内能极大提升性能。
- 列限定符(Column Qualifier):列族内的具体列,可以在写入时动态添加,无需预定义。
- 时间戳(Timestamp):每个单元格(Cell,即由行键、列族、列限定符确定的特定数据点)可以存储多个版本的数据,由时间戳区分。默认按时间戳倒序排列,优先读取最新版本。
- 一个具体的单元格由
RowKey + Column Family: Column Qualifier + Timestamp唯一确定,其值为一个字节数组。
- 物理存储:Region、HFile与MemStore
- Region:表在水平方向上被自动划分为多个Region,每个Region负责表中一段连续的行键范围。Region是HBase分布式存储和负载均衡的基本单位,由RegionServer负责管理。
- 存储层次:
- MemStore:位于每个RegionServer内存中的写缓冲区。当客户端写入数据时,首先顺序写入WAL(Write-Ahead Log,预写日志,用于故障恢复),然后写入对应的MemStore。MemStore中的数据按行键排序。
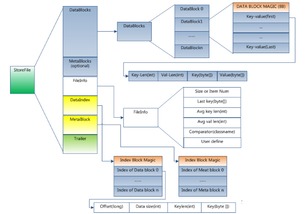
- HFile:当MemStore的大小达到阈值后,其内容会被异步刷新(Flush)到HDFS上,形成一个不可变的、经过排序的存储文件——HFile。HFile内部采用多层索引结构(如布隆过滤器、块索引),以支持高效的键值查找。
- Compaction:随着写入不断进行,会产生大量小HFile。HBase会定期执行Compaction操作,将小文件合并成大文件,并清理已删除或过期的数据,以优化读取性能和存储效率。主要分为Minor Compaction和Major Compaction。
二、HBase的数据处理
HBase的数据处理主要围绕其读写路径展开。
- 写入流程:
- 客户端通过ZooKeeper定位到负责目标行键的RegionServer。
- 数据首先被追加写入到WAL,确保持久性。
- 数据被写入对应Region的MemStore中。
- 当MemStore满时,触发Flush,生成新的HFile存储到HDFS。
- 此设计使得写入速度极快,本质上是顺序写入内存和日志。
- 读取流程:
- 同样先定位到目标RegionServer和Region。
- 读取操作需要合并来自多个源的数据以返回最新版本:首先检查MemStore(内存中的最新数据),然后查找BlockCache(读缓存),最后在磁盘上的多个HFile中进行查找(利用索引快速定位)。
- 为了加速读取,HBase使用布隆过滤器来快速判断某个HFile中是否包含目标行键,避免不必要的磁盘IO。
- 扫描(Scan):
- 支持高效的范围查询,通过设置起始和结束行键,可以顺序遍历一个Region或多个Region。
- 利用行键有序存储和Region的划分,扫描性能很高。
三、HBase提供的存储支持服务
HBase不仅仅是一个存储系统,它通过一系列内置服务为上层应用提供了强大的数据管理能力。
- 高可用性与自动故障恢复:
- RegionServer容错:如果某个RegionServer宕机,其负责的Regions会被Master服务器迅速重新分配到其他健康的RegionServer上,并通过WAL进行数据恢复。
- Master高可用:支持多Master主备,避免单点故障。
- 底层依赖HDFS的多副本机制,保证数据本身的高可靠。
- 强一致性与事务支持:
- 提供行级原子性:对同一行的所有读写操作都是原子的。
- 支持单行事务,确保对一行的Put操作要么完全成功,要么完全失败。
- 通过Check-And-Put等操作实现简单的乐观锁。
- 可扩展性与负载均衡:
- 线性扩展:通过简单地增加RegionServer节点,即可水平扩展集群的存储容量和吞吐量。
- 自动负载均衡:Master会监控Region的分布和负载情况,自动将Region从繁忙的服务器迁移到空闲的服务器。
- 自动分区(Region Split):当某个Region数据量过大时,会自动分裂成两个子Region,保持每个Region大小适中。
- 数据管理与维护服务:
- TTL(Time-To-Live):支持在列族级别设置数据的存活时间,过期数据会在Major Compaction时被自动清理。
- 版本管理与数据压缩:如前所述,通过多版本和Compaction机制管理数据生命周期和存储空间。
- 与Hadoop生态无缝集成:可以方便地使用MapReduce、Spark、Flink等计算框架直接处理HBase中的数据,也支持作为这些框架作业的输出目的地。
- 监控与运维支持:
- 通过集成的Web UI(Master和RegionServer界面)以及丰富的JMX指标,提供集群状态、性能监控和诊断能力。
- 与Apache Ambari、Cloudera Manager等集群管理工具深度集成,简化运维。
###
HBase通过其独特的面向列的存储格式(基于行键、列族、HFile)、先写日志再写内存的高效处理流程,以及内置的高可用、强一致、可扩展的存储支持服务,构建了一个非常适合海量数据随机实时读写和范围查询的存储解决方案。它是构建在HDFS之上、弥补其随机访问能力不足的关键服务层,广泛应用于互联网、金融、电信等领域的实时大数据场景。
如若转载,请注明出处:http://www.qjxmcdh.com/product/11.html
更新时间:2026-06-18 19:27:05