深入解析 栈空间与堆空间中的数据存储机制及其支持服务
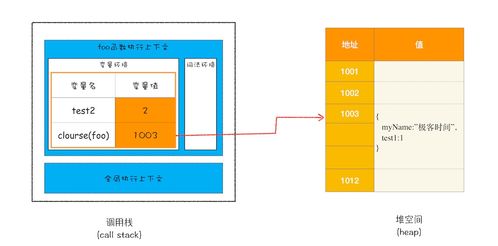
在计算机科学中,程序运行时数据的存储与管理是系统性能与稳定性的核心。栈空间(Stack)和堆空间(Heap)是两种关键的内存区域,它们以不同的方式存储数据,共同支撑着数据处理与存储服务。理解它们的差异对于编程、系统设计和性能优化至关重要。
一、栈空间:快速有序的数据存储
栈空间是一种线性数据结构,采用“后进先出”(LIFO)原则。它主要用于存储局部变量、函数参数和返回地址等临时数据。其特点包括:
- 自动管理:栈内存由编译器自动分配和释放,无需手动干预。当函数调用结束时,其栈帧会被弹出,内存立即回收。
- 高效快速:由于内存分配在连续地址上,且操作仅限于栈顶,存取速度极快。
- 容量有限:栈空间通常较小(例如在MB级别),过度使用可能导致栈溢出错误。
例如,在C++中,局部变量int x = 10;会存储在栈上,函数执行完毕后自动清除。
二、堆空间:动态灵活的数据存储
堆空间是一种非结构化的内存区域,用于动态分配数据,如对象、数组或大型数据结构。其特点包括:
- 手动管理:在C/C++等语言中,堆内存需通过
malloc或new显式分配,并通过free或delete释放,否则可能导致内存泄漏。 - 容量较大:堆空间通常远大于栈,可利用系统大部分可用内存。
- 灵活但较慢:分配和释放涉及复杂的内存管理算法,速度相对较慢,且可能产生内存碎片。
例如,在Java中,Object obj = new Object();会在堆上创建对象,并由垃圾回收器自动管理生命周期。
三、数据处理与存储支持服务
栈和堆的协作,为现代计算提供了关键支持:
- 运行时环境:编程语言(如Java虚拟机、.NET CLR)利用栈管理线程执行,堆管理对象存储,确保程序高效运行。
- 内存管理服务:操作系统通过虚拟内存系统协调栈和堆,提供隔离、保护和交换机制,避免内存冲突。
- 性能优化工具:分析工具(如Valgrind、Visual Studio Profiler)监控栈/堆使用,帮助开发者检测内存泄漏或溢出问题。
- 分布式系统支持:在大数据平台(如Hadoop、Spark)中,堆空间用于缓存处理数据,栈则管理任务执行状态,提升分布式处理效率。
四、实践应用与注意事项
- 栈适用场景:小型临时变量、递归调用控制(需注意深度限制)。
- 堆适用场景:生命周期长或大小不确定的数据(如文件缓存、数据库连接池)。
- 安全与效率平衡:过度依赖堆可能引发内存碎片;滥用栈则易导致溢出。现代语言(如Rust)通过所有权模型,在编译时优化内存管理,结合两者优势。
栈空间和堆空间是数据存储的基石,它们的差异化管理机制使得程序既能高效执行短期任务,又能灵活处理复杂数据。随着云计算和边缘计算发展,内存管理服务不断演进,例如通过智能分配算法和硬件加速,进一步提升了数据处理能力,支撑着从嵌入式设备到大型服务器的广泛应用。
如若转载,请注明出处:http://www.qjxmcdh.com/product/20.html
更新时间:2026-06-18 19:02:25