亿级流量系统架构之如何支撑百亿级数据的存储与计算
在当今数据爆炸的时代,面对亿级流量与百亿级数据的双重挑战,构建一个既能高效存储海量数据,又能实时进行复杂计算的系统架构,已成为众多互联网企业的核心课题。这不仅是技术能力的体现,更是业务持续创新与稳定运行的基石。本文将深入探讨支撑百亿级数据处理与存储的关键架构设计思路与服务支持。
一、 核心挑战:规模、速度与成本
我们需要明确百亿级数据场景下的核心挑战:
- 数据规模巨大:数据量以百亿、千亿条计,传统单机数据库和存储方案完全无法应对。
- 读写压力极高:亿级日活带来的并发读写请求,要求存储系统具备极高的吞吐量和低延迟。
- 计算复杂度高:从简单的统计报表到复杂的实时推荐、风控分析,计算任务多样且繁重。
- 成本控制敏感:海量数据存储与计算资源消耗巨大,必须在性能和成本之间找到最佳平衡点。
- 可扩展性与高可用性:系统必须能够随着业务增长平滑扩容,并保证7x24小时不间断服务。
二、 存储架构:分层设计与选型
应对百亿级数据存储,关键在于“分而治之”和“因地制宜”。
- 在线热数据存储:
- 需求:低延迟、高并发、强一致性读写,支撑核心交易与用户实时交互。
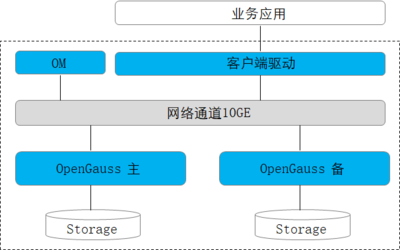
- 方案:分布式关系型数据库(如阿里云PolarDB、腾讯云TDSQL)或NewSQL数据库(如TiDB)。它们通过分库分表(或自动分片)、多副本机制,在保持SQL兼容性和ACID事务的实现了水平扩展。对于结构化要求不高的场景,宽列存储(如HBase、Cassandra)也是处理海量Key-Value数据的利器。
- 离线温冷数据存储:
- 需求:海量、低成本、高吞吐的批量读写,用于历史数据归档、批量分析与备份。
- 方案:分布式对象存储是绝对主流,如AWS S3、阿里云OSS、腾讯云COS。它们提供了近乎无限的容量、极高的持久性和极低的存储成本,是数据湖的基石。配合分布式文件系统(如HDFS)使用,可直接为大数据计算引擎提供数据源。
- 检索与分析型存储:
- 需求:复杂的多维度查询、全文搜索与实时分析。
- 方案:Elasticsearch 用于日志、监控数据和需要强大全文检索的场景;ClickHouse 或 Doris 作为OLAP(联机分析处理)引擎,专为高速聚合查询和分析报表设计,在处理百亿级数据时的查询速度远超传统方案。
架构实践:采用Lambda架构或Kappa架构作为数据流的顶层设计,将实时处理链路与离线批处理链路分离或统一,确保数据既能被实时消费,也能进行深度历史挖掘。
三、 计算架构:批流一体与弹性调度
计算的核心目标是高效、准确地将海量数据转化为业务价值。
- 批处理计算:
- 场景:T+1报表、数据仓库ETL、大规模机器学习训练。
- 引擎:Apache Spark 是当今事实上的标准,其基于内存的DAG计算模型,极大提升了批量数据处理的性能。它能够轻松应对百亿数据级别的复杂ETL和聚合分析。
- 流处理计算:
- 场景:实时监控、实时风控、实时推荐、实时大屏。
- 引擎:Apache Flink 凭借其高吞吐、低延迟、精确一次(Exactly-Once)的状态一致性保证,成为流处理领域的王者。它能够处理每秒数百万事件的数据流,并实现复杂的窗口计算和状态管理。
- 批流融合与统一:
- 现代数据架构趋势是 “批流一体” 。Flink和Spark(Structured Streaming)都致力于用同一套API和引擎处理批与流数据,简化开发运维复杂度。数据湖格式如 Apache Iceberg、Hudi 支持在对象存储上实现高效的增量更新和流式读写,进一步打通批流界限。
- 资源调度与治理:
- 调度器:Apache YARN 或 Kubernetes 是集群资源的“大脑”。K8s凭借其强大的容器化管理和弹性伸缩能力,在现代云原生架构中越来越流行。
- 计算治理:通过工作流调度系统(如Apache Airflow、DolphinScheduler)编排复杂的计算任务依赖;利用元数据管理(如Apache Atlas)和数据血缘追踪工具保障数据质量与合规。
四、 数据处理与存储支持服务:平台化与智能化
将上述组件有机整合,并提供给业务方便捷使用的,正是统一的数据平台与服务。
- 一站式数据开发平台:提供从数据采集、同步、开发、调试、调度到运维监控的全生命周期Web化操作界面,降低大数据开发门槛。
- 统一元数据与服务发现:中心化管理所有数据表、字段、计算任务的元信息,提供数据地图、血缘分折和全局检索能力。
- 智能资源优化:基于历史运行数据和机器学习模型,自动推荐或动态调整计算任务的内存、CPU配置,实现成本最优。自动识别冷数据并降档存储至更便宜的介质。
- 稳定可靠的底层服务:
- 高性能网络:数据中心内部高速RDMA网络,减少数据传输开销。
- 分布式缓存:在计算与存储层之间,利用Redis、Memcached等构建多层缓存体系,缓解热点访问压力。
- 消息队列:Apache Kafka 或 Pulsar 作为数据流的“中枢神经系统”,负责解耦生产与消费,缓冲流量高峰,保障数据不丢失。
五、 与展望
支撑百亿级数据的存储与计算,并非单一技术选型的胜利,而是一个系统性工程。它要求我们:
- 在架构上,遵循分层解耦、批流融合、弹性可扩展的原则。
- 在选型上,结合数据特性和访问模式,混合使用多种数据库与存储引擎。
- 在实施上,通过平台化服务将复杂技术封装,赋能业务团队。
- 在运维上,持续关注资源利用率与成本,利用自动化与智能化手段进行优化。
随着云原生、Serverless、存算分离等技术的深入发展,以及AI for DataOps的应用,构建和管理超大规模数据系统的复杂度有望进一步降低,使企业能够更专注于从数据中挖掘核心价值,驱动业务持续增长。
如若转载,请注明出处:http://www.qjxmcdh.com/product/7.html
更新时间:2026-06-18 06:33:41