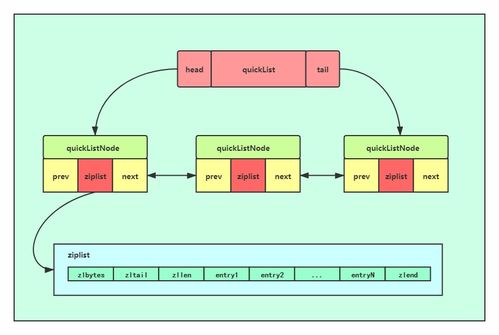
五种存储类型及其底层数据结构 数据处理与存储支持的基石
在数据驱动的时代,高效、可靠的数据存储是支撑各类应用和服务的关键。数据处理和存储支持服务需要根据不同的业务场景、性能要求和成本考量,选择合适的存储类型及其底层数据结构。本文将系统性地阐述五种主流的存储类型及其核心数据结构,并分析它们如何协同支撑现代数据处理与存储服务。
一、关系型数据库存储
核心数据结构:B+树、哈希表
关系型数据库(如MySQL、PostgreSQL)以表格形式组织数据,强调ACID(原子性、一致性、隔离性、持久性)特性。其底层索引通常采用B+树,它能高效支持范围查询和顺序访问,同时保持较低的树高度以确保磁盘I/O效率。主键索引多使用B+树,而哈希表则常用于内存中的临时表或特定优化场景,以实现O(1)时间复杂度的精确匹配查询。
在数据处理与存储服务中的角色:作为事务处理(OLTP)的核心,支撑订单、用户信息等需要强一致性和复杂关联查询的业务。
二、键值存储
核心数据结构:哈希表、跳表、LSM树
键值存储(如Redis、DynamoDB)以简单的键值对形式存储数据,追求极高的读写性能。内存型键值存储(如Redis)常使用哈希表实现O(1)的读写,同时使用跳表(Skip List)来支持有序集合等高级数据结构。而面向持久化的键值存储(如LevelDB、RocksDB)则广泛采用日志结构合并树(LSM-Tree),它通过将随机写转换为顺序写,极大地提升了写入吞吐量,非常适合写多读少的场景。
在数据处理与存储服务中的角色:常用于缓存、会话存储、实时排行榜等对延迟极其敏感的场景,是提升应用性能的关键组件。
三、文档存储
核心数据结构:B树、JSON/BSON编码
文档数据库(如MongoDB、Couchbase)以半结构化的文档(通常为JSON或BSON格式)为基本存储单元。其底层存储引擎可能使用B树或其变种来构建索引,支持对文档内部字段的高效查询。文档的灵活模式使其能够轻松存储嵌套和异构数据。
在数据处理与存储服务中的角色:完美适配内容管理、产品目录、用户配置文件等模式灵活多变的应用,简化了开发模型。
四、列式存储
核心数据结构:列式数据块、位图索引
列式数据库(如ClickHouse、Apache Cassandra)将数据按列而非按行存储。每一列的数据被独立存储和压缩成连续的数据块。这种结构特别适合使用位图索引等技术进行高效压缩和快速聚合查询。当查询只涉及少数列时,系统只需读取特定列的数据,极大地减少了I/O。
在数据处理与存储服务中的角色:是数据仓库、商业智能(BI)和分析型处理(OLAP)的支柱,专为海量数据的快速扫描和复杂聚合分析而优化。
五、搜索引擎存储
核心数据结构:倒排索引、FST
搜索引擎(如Elasticsearch、Apache Solr)的核心是为全文检索而设计。其最核心的数据结构是倒排索引,它建立了从词汇到包含该词汇的文档列表的映射,使得关键词查询极为迅速。对于词条字典,常使用有限状态转换器(FST)等高效数据结构进行压缩存储,以在内存中容纳巨大的词汇表。
在数据处理与存储服务中的角色:提供强大的全文搜索、日志和事件数据分析能力,是构建搜索引擎、日志监控平台和复杂查询应用的基础。
协同构建数据处理与存储服务体系
现代数据处理和存储支持服务很少孤立地使用单一存储类型。一个典型的微服务架构或数据平台,往往由上述多种存储系统协同构成:
- 关系型数据库处理核心交易和关系数据。
- 键值存储作为高速缓存层,抵挡后端压力。
- 文档存储承载灵活的业务数据模型。
- 列式存储服务于海量数据分析。
- 搜索引擎提供高效的数据检索与探索能力。
理解每种存储类型背后的核心数据结构(如B+树之于范围查询,LSM树之于高速写入,倒排索引之于全文搜索),是进行技术选型、性能调优和系统设计的根本。正是这些精妙的数据结构,构成了数据处理与存储服务的坚实底座,使我们能够从容应对从高并发事务到海量数据分析的各种挑战。
如若转载,请注明出处:http://www.qjxmcdh.com/product/4.html
更新时间:2026-06-18 05:30:09